
JSON

JSON (JavaScript Object Notation) は、テキストベースで人間が読みやすく、Web APIや設定ファイルなどで広く利用されています。
• 特徴: 行ベース(Row-based)柔軟性が最大の利点です。
• 欠点: データの規模が大きくなると、すべてのレコードで「キー名」を繰り返すためストレージ効率が悪化し、クエリの実行速度も低下します。また、スキーマの強制力がないため、データの不整合が起きやすいという課題もあります。
Apache Avro
Avro はバイナリ形式の行ベースフォーマットであり、Kafkaなどのリアルタイムストリーミングやメッセージキューによく使用されます。
• 特徴: 非常にコンパクトなバイナリ形式で、書き込み効率に優れています。スキーマがデータと共に保存されるため、スキーマの進化(Schema Evolution)にも対応しています。
• 用途: レコード全体を頻繁に追加・取得する必要がある「書き込み重視」のワークロードに最適です
Apache Parquet

Parquet はオープンソースの列指向(Columnar)データ保存形式であり、現代の大規模分析(OLAP)において最も標準的な選択肢です。
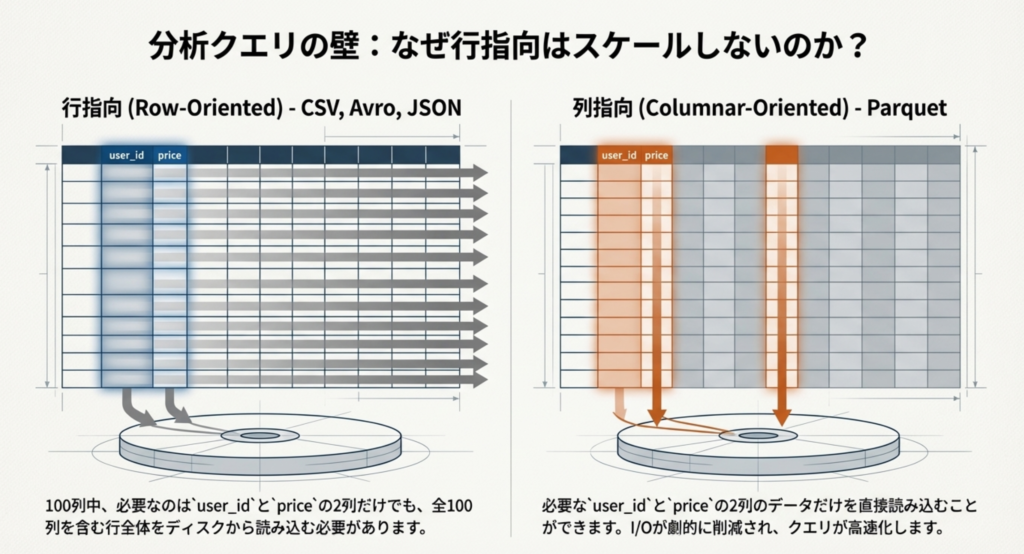
• 特徴: データを列ごとに整理して保存するため、クエリに関係のない列を読み飛ばす「列のプルーニング(Column Pruning)」が可能です。
• 利点: 列ごとに似たデータが集まるため圧縮効率が非常に高く、クラウドストレージのコスト削減とクエリの高速化を同時に実現します。例えば、Amazon S3でCSVからParquetに変換するだけで、スキャン量を99%以上削減し、コストを大幅に抑えられるケースもあります。

Apache Iceberg
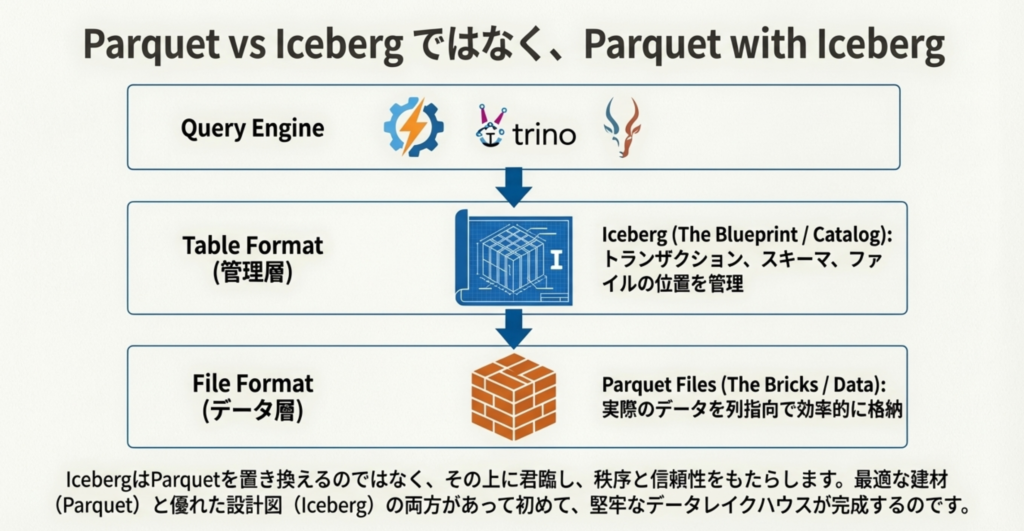
重要なのは、IcebergはParquetやAvroのような「ファイル形式」ではなく、それらを管理する「テーブル形式」であるという点です。
• 役割: Parquetなどのファイル群の上にメタデータレイヤーを構築し、データベースのような信頼性を提供します。
主な機能

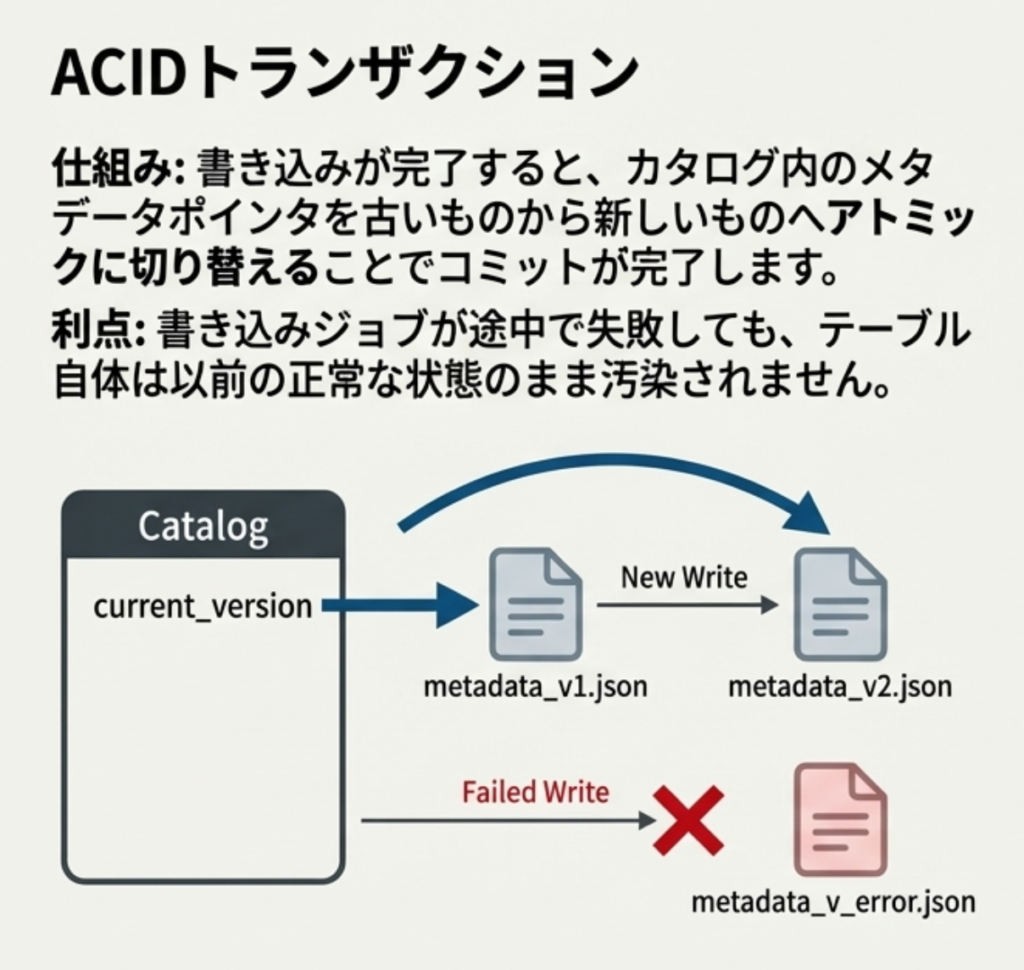
ACIDトランザクション
書き込み中に読み取りを阻害せず、アトミックなコミットを可能にします。
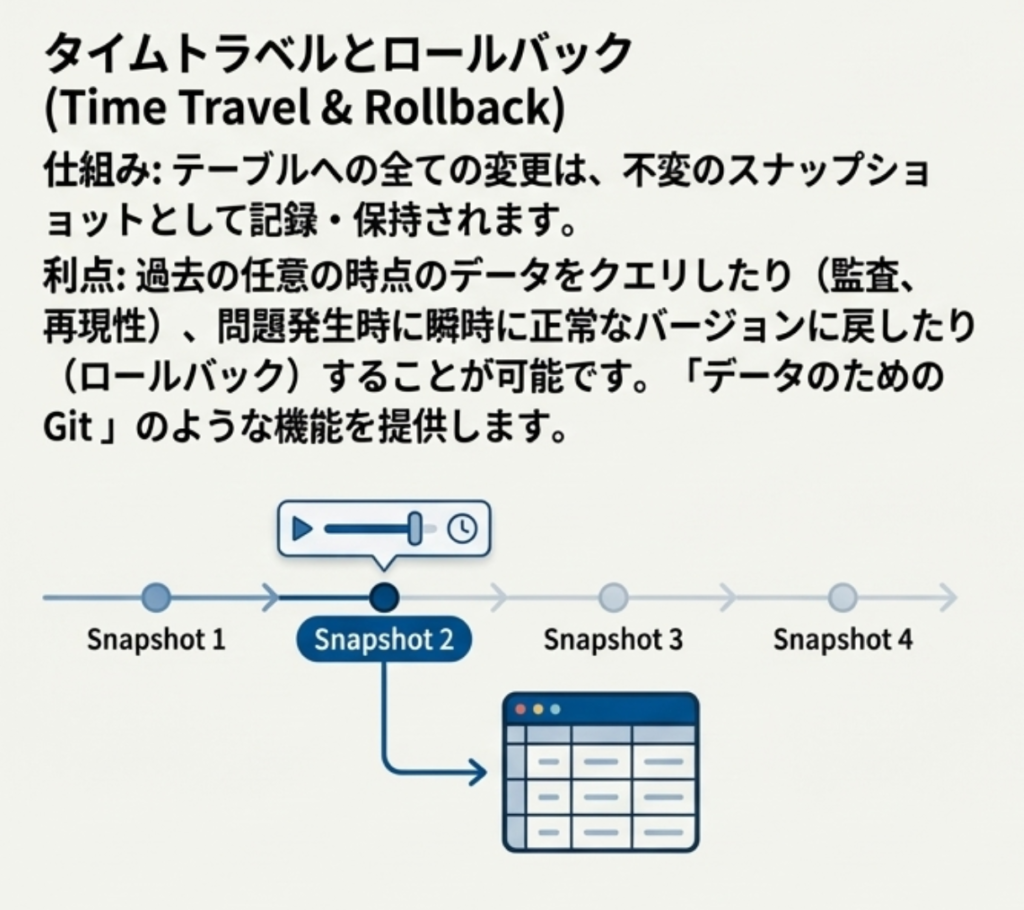
タイムトラベル
過去のスナップショットにアクセスし、特定の時点の状態を照会できます。
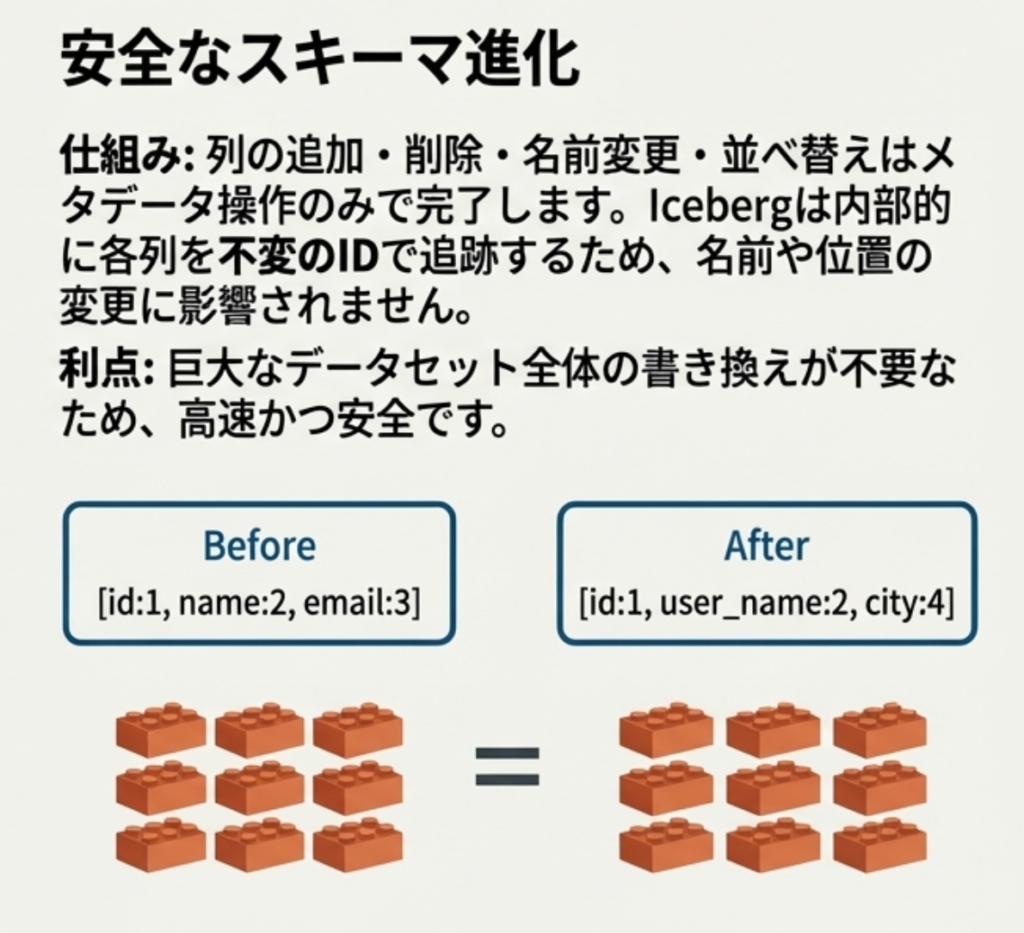
スキーマ・パーティション進化
テーブルを再作成することなく、列の追加やパーティション設定の変更が可能です。
パフォーマンス最適化:
ファイルレベルの統計情報を保持し、クエリに必要な最小限のファイルだけを正確に特定します。

データレイクハウスアーキテクチャの全体像

競合とエコシステム
Icebergはオープンテーブルフォーマットの主要な選択肢ですが、エコシステムには他にも有力なプロジェクトが存在します。

各フォーマットの役割と違い
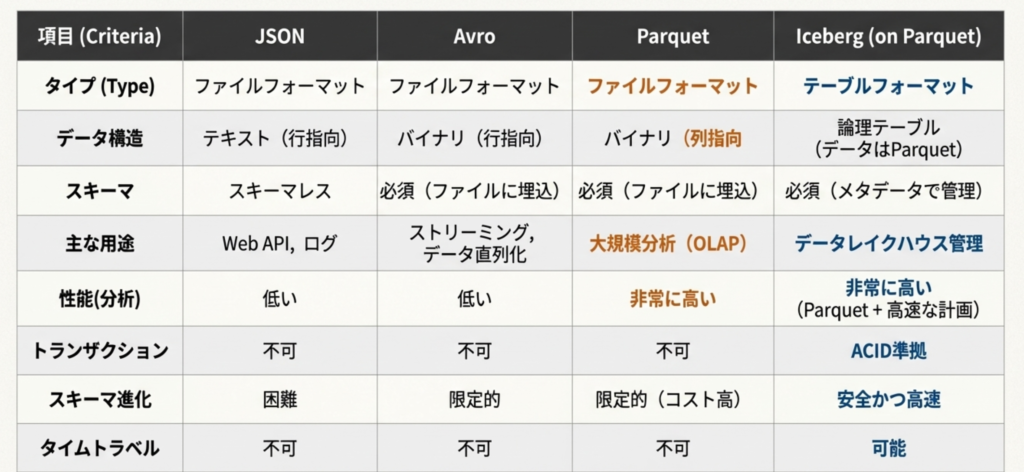
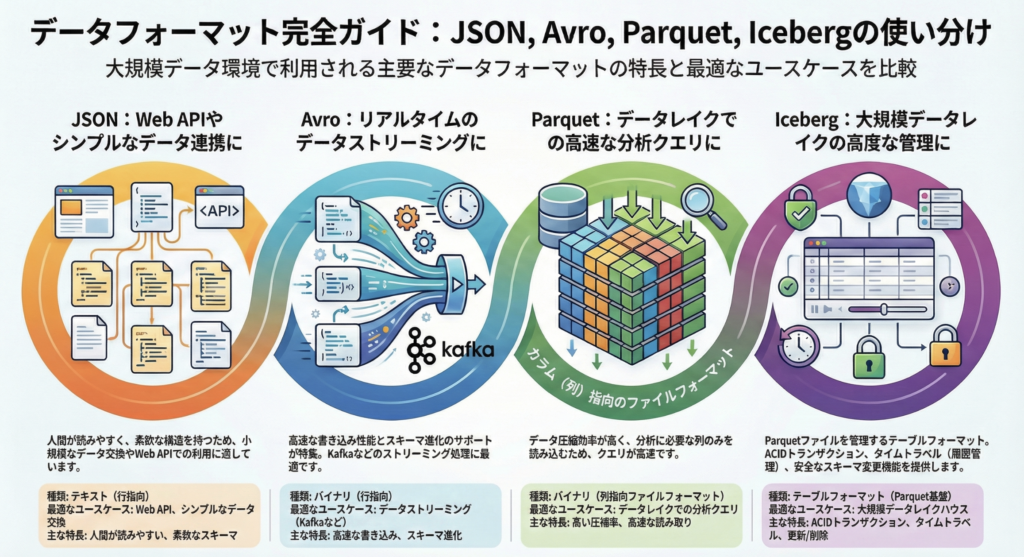
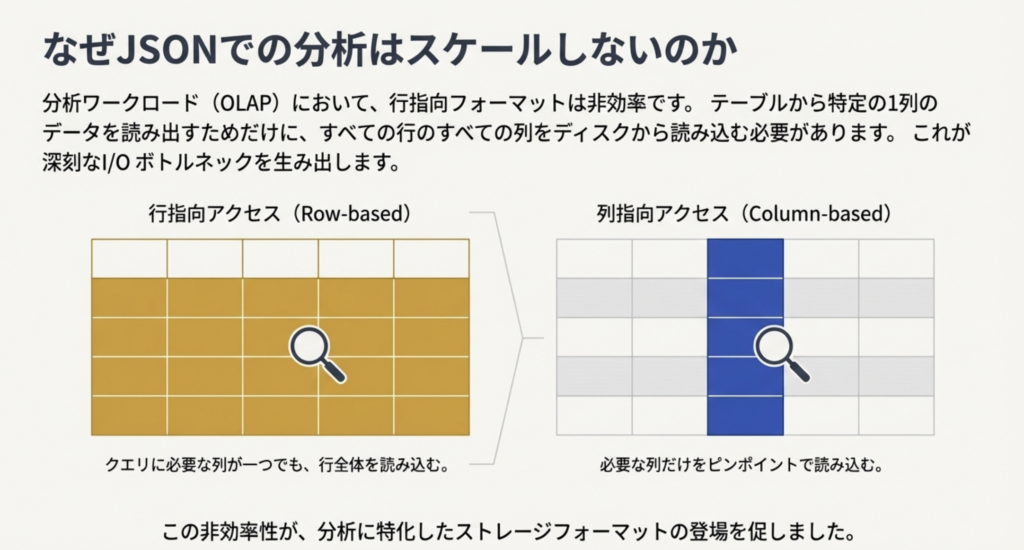
- 分析ワークロードにおいて、行指向フォーマットは非効率。クエリに必要な列が一つでも、行と列全体を読み込む必要があるため。(列指向フォーマットであれば、必要な列を読み込むだけでよい)
- Icebargテーブルによって、レイクハウスアーキテクチャを実現。ACIDトランザクションやスナップショットが実現。

コメント